Optimizing Database Queries - Navigating One-to-Many Relationships with Xata's New Approach
Introduction
In the realm of database management and API development, one of the most common challenges developers face is optimizing the retrieval of data from one-to-many relationships while avoiding the notorious N+1 problem. 🦋 Xata, a cutting-edge database solution, has introduced a new approach to address this issue, making it more efficient and developer-friendly. In this article, we’ll delve into Xata’s innovative syntax for navigating one-to-many relationships, providing real-world examples to illustrate its advantages.
Understanding the N+1 Problem
The N+1 problem is a common performance issue that arises when retrieving data from one-to-many relationships in a database. It occurs when you retrieve a collection of primary objects along with their associated objects. For each primary object, an additional query is executed to fetch its associated objects. This can result in a cascade of database queries, leading to significant performance bottlenecks.
To visualize the N+1 problem, imagine a scenario where you have two related database tables: Authors and Books. Each author can have multiple books, and you want to retrieve a list of authors along with their books.
Here’s what the database schema might look like:
Authors Table:
| AuthorID | AuthorName |
|---|---|
| 1 | John Doe |
| 2 | Jane Smith |
| 3 | David Johnson |
Books Table:
| BookID | AuthorID | Title |
|---|---|---|
| 1 | 1 | The Great Novel |
| 2 | 1 | Mystery Unveiled |
| 3 | 2 | Adventure Awaits |
| 4 | 3 | Coding Mastery |
Now, let’s say you want to retrieve a list of authors along with their books using a naive approach that leads to the N+1 problem.
Naive Query:
- Retrieve all authors.
- For each author, retrieve their books.
In this scenario, you would end up with multiple queries, specifically N+1 queries, where N is the number of authors. Here’s what the sequence of queries would look like:
Query 1: Retrieve all authors
Query 2: Retrieve books for AuthorID 1
Query 3: Retrieve books for AuthorID 2
Query 4: Retrieve books for AuthorID 3
As you can see, for each author, you execute an additional query to retrieve their books. This is the essence of the N+1 problem: you end up with N+1 queries when you could have ideally retrieved the data in a single query.
Xata’s Solution: Navigating One-to-Many Relationships
Xata recognized the need for a more efficient approach to navigating one-to-many relationships. To address this challenge, they introduced a new syntax that simplifies the process, eliminates unnecessary round trips, and optimizes performance. Let’s explore this approach with the above-mentioned example in the Xata Database. I want you to work on this hands-on and not just learn by seeing the code snippet.
If you are new to Xata, then I recommend you read the getting started guide to understand better.
Create Database
Once you have an account, you can create a new database in your workspace. Provide the name of your database and select a region for it. Then click “Create” and the database is created.
Create Tables
We need two tables, one is for author and the other for books. So, create a table with the columns name in the authors table and title and author in the books table. We don’t need to unique author ID since Xata creates a unique ID every time we insert a new value into the table. While defining the author column in the books table use the link to table column type and link it to the authors table. Once you create you will be able to see the referenced values in the books table. The below schema will you understand better. Add the authors and book titles like the one above and you can modify it as you wish.
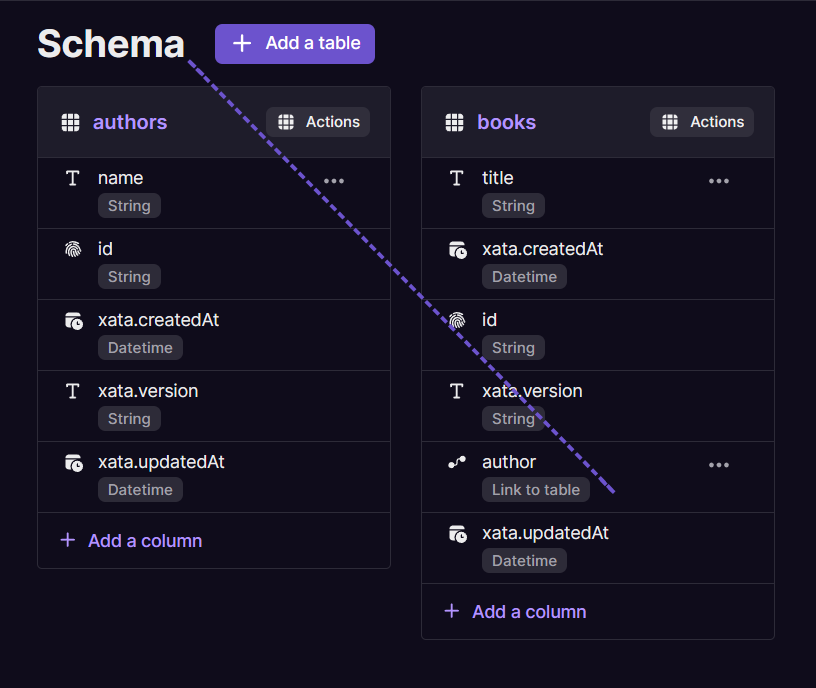
Playground
Once you are done with the values. We can now use Xata’s playground to understand our problem. Traditionally, you’d fetch authors and then make separate queries for each author’s books. Result? N+1 queries, where N is the number of authors. Yikes! Performance bottlenecks and database round trips galore. 😬
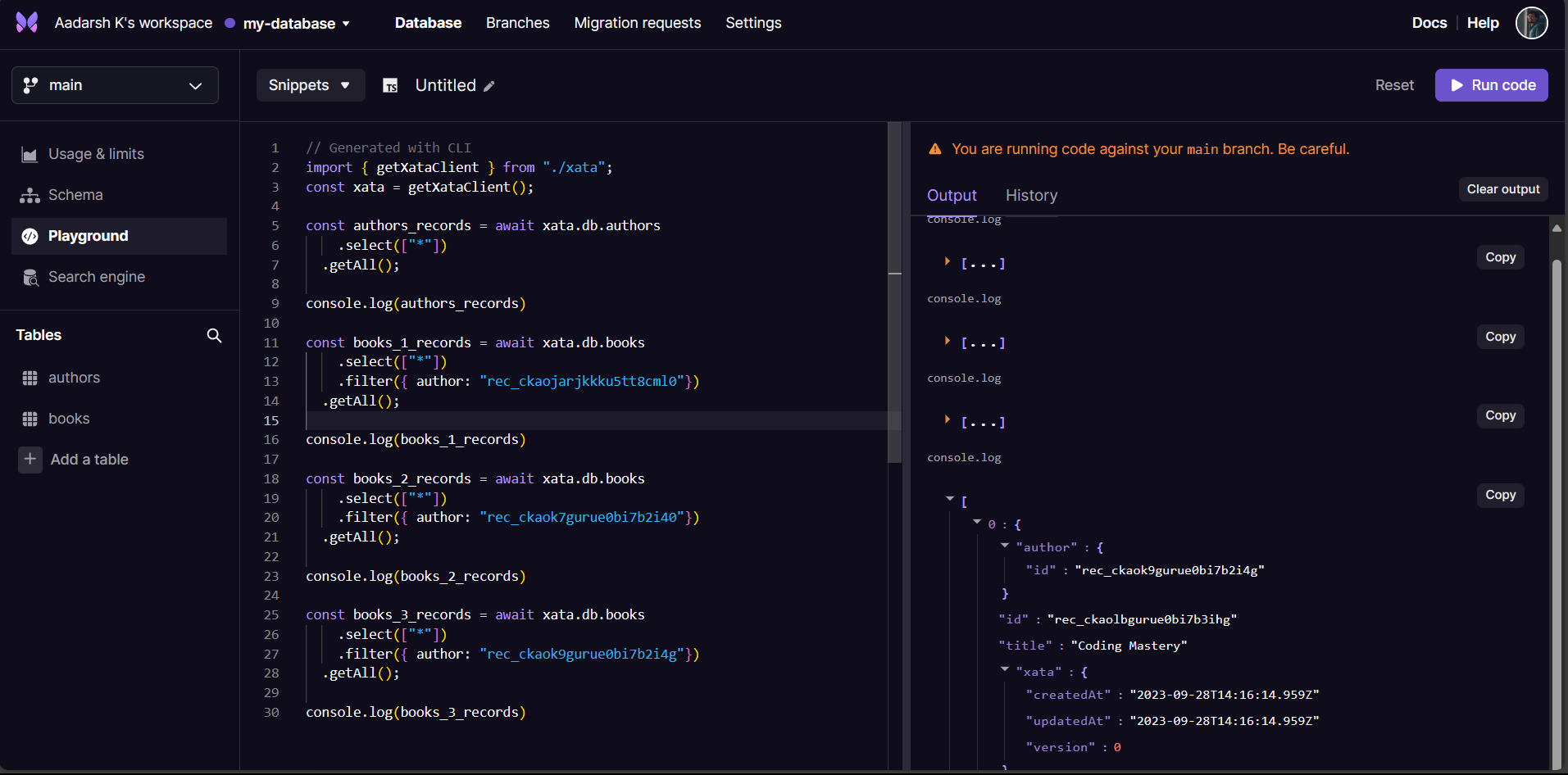
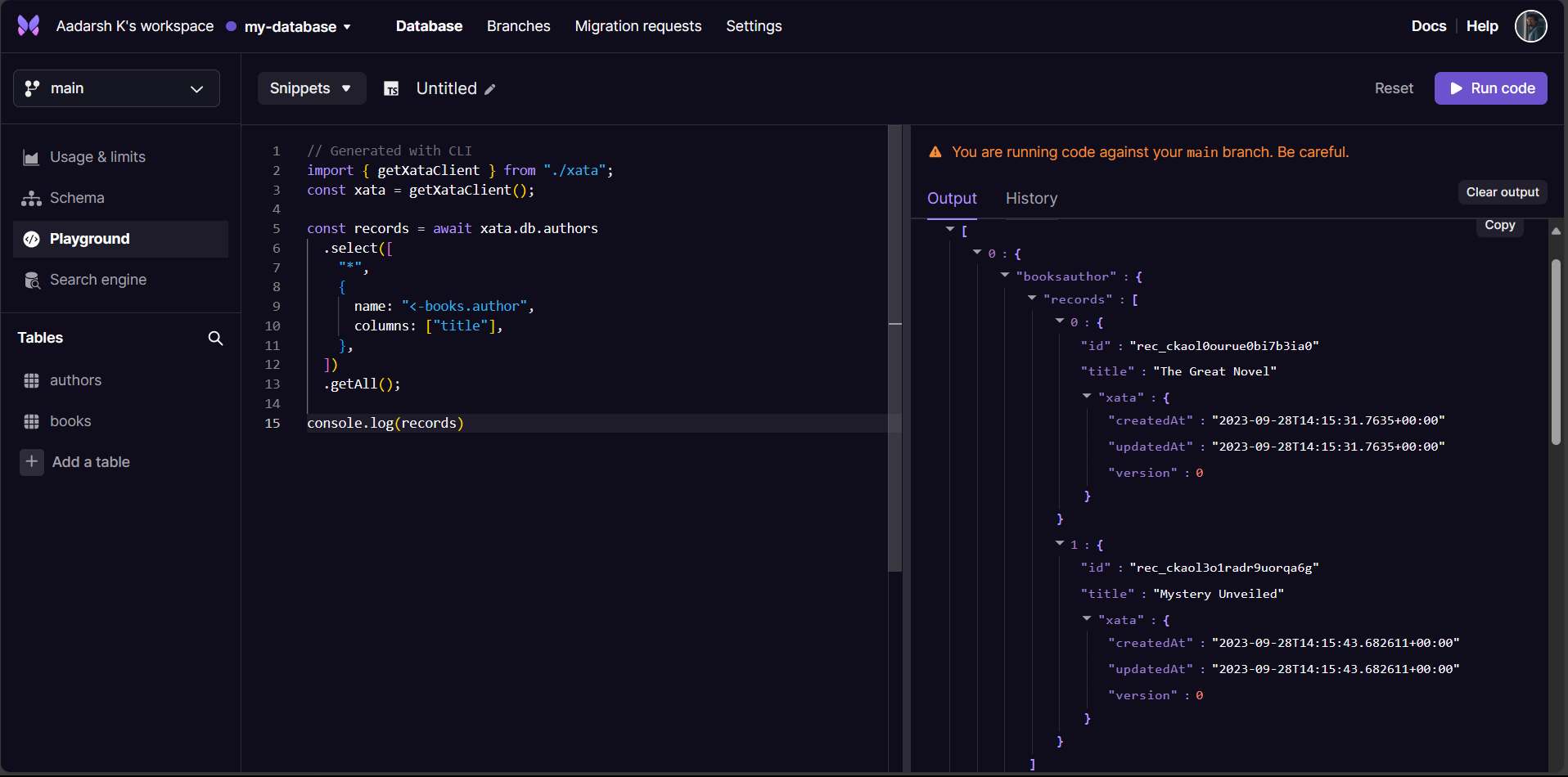
With the new column expressions feature, you can do that in a single request. Just use the <- prefix to indicate the reverse link, and specify the columns you want from the related table. You’ll get a nested JSON document with all the data you need.
1
2
3
4
5
6
7
8
9
const records = await xata.db.authors
.select([
"*",
{
name: "<-books.author",
columns: ["title"],
},
])
.getAll();
In this query, we specify the columns we want to retrieve, including a column expression that navigates in reverse along the “books” link defined in the “Authors” table. This reverse navigation establishes a one-to-many relationship between authors and books. We also specify which fields from the “Books” table should be included in the query result.
Benefits of Xata’s Approach
-
Elimination of N+1 Problem: By using Xata’s syntax, we can fetch all the data we need with a single request, avoiding any unnecessary round trips and repetitive code. This approach mitigates the N+1 problem, resulting in significantly improved performance.
-
Efficiency: Xata’s syntax simplifies the process of retrieving related data, making it more developer-friendly. It reduces the complexity of code and ensures that you get exactly the data you want in an efficient manner.
-
Advanced Configuration: Xata’s approach allows for advanced configuration, such as sorting options and pagination, enabling developers to tailor their queries to specific requirements.
-
PostgreSQL Implementation: Xata has implemented this approach efficiently in PostgreSQL, leveraging subqueries and the
json_agg()function to simplify complex queries, improve query performance, and promote code reusability.
Conclusion
Xata’s approach to solving the N+1 problem with its intuitive syntax simplifies the process of navigating one-to-many relationships, providing an efficient and developer-friendly solution. By optimizing data retrieval and eliminating unnecessary database round trips, Xata enhances the performance and productivity of applications that rely on complex data relationships. Developers can now focus on building powerful applications without worrying about inefficient queries.
Thanks for the read!